多线程并发概述
多线程并发是指在单个程序中同时运行多个线程,通过并行或交替执行任务来提升性能和资源利用率的编程模型。在ArkTS应用开发中,多线程并发适用于多种业务场景,常见的业务场景主要分为以下三类:
-
业务逻辑包含大量计算或频繁的I/O读写等需要长时间执行的任务,例如图片和视频的编解码、文件的压缩与解压缩、数据库操作等场景。
-
业务逻辑包括监听和定期采集数据等需要长时间保持运行的任务,例如定期采集传感器数据的场景。
-
业务逻辑跟随主线程的生命周期,或与主线程绑定的任务,例如在游戏中的业务场景。
并发模型用于实现不同应用场景中的并发任务。常见的并发模型有基于内存共享的模型和基于消息通信的模型。
Actor并发模型是基于消息通信的典型并发模型。开发者无需处理锁带来的复杂问题,且具备高并发度,因此应用广泛。
当前ArkTS提供了TaskPool和Worker两种并发能力,两者均基于Actor并发模型实现。
Actor并发模型和内存共享并发模型的具体对比请见多线程并发模型。
多线程并发模型
内存共享并发模型指多线程同时执行任务,这些线程依赖同一内存资源并且都有权限访问,线程访问内存前需要抢占并锁定内存的使用权,没有抢占到内存的线程需要等待其他线程释放使用权再执行。
Actor并发模型每一个线程都是一个独立Actor,每个Actor有自己独立的内存,Actor之间通过消息传递机制触发对方Actor的行为,不同Actor之间不能直接访问对方的内存空间。
Actor并发模型与内存共享并发模型相比,不同线程间的内存是隔离的,因此不会发生线程竞争同一内存资源的情况。无需处理内存上锁问题,从而提高开发效率。
Actor并发模型中,不同Actor之间不共享内存,需通过消息传递机制传递任务和结果。
本文以经典的生产者消费者问题为例,分析这两种模型在解决问题时的差异。
内存共享模型
以下示例伪代码和示意图展示了如何使用内存共享模型解决生产者消费者问题。
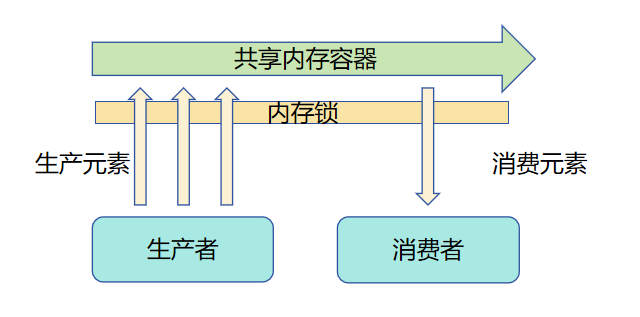
为了避免不同生产者或消费者同时访问同一块共享内存容器时产生脏读、脏写现象,同一时间只能有一个生产者或消费者访问该容器。即不同生产者和消费者需争夺使用容器的锁。当一个角色获取锁后,其他角色需等待该角色释放锁,才能重新尝试获取锁以访问该容器。
// 此段示例为伪代码仅作为逻辑示意,便于开发者理解使用内存共享模型和Actor模型的区别
class Queue {
// ...
push(value: number) {
// ...
}
empty(): boolean {
// ...
return true;
}
pop(value: number): number {
// ...
return value;
}
// ...
}
class Mutex {
// ...
lock(): boolean {
// ...
return true;
}
unlock() {
// ...
}
// ...
}
class BufferQueue {
queue: Queue = new Queue();
mutex: Mutex = new Mutex();
add(value: number) {
// 尝试获取锁
if (this.mutex.lock()) {
this.queue.push(value);
this.mutex.unlock();
}
}
take(value: number): number {
let res: number = 0;
// 尝试获取锁
if (this.mutex.lock()) {
if (this.queue.empty()) {
res = 1;
return res;
}
let num: number = this.queue.pop(value);
this.mutex.unlock();
res = num;
}
return res;
}
}
// 构造一段全局共享的内存
let g_bufferQueue = new BufferQueue();
class Producer {
constructor() {
}
run() {
let value = Math.random();
// 跨线程访问bufferQueue对象
g_bufferQueue.add(value);
}
}
class ConsumerTest {
constructor() {
}
run() {
// 跨线程访问bufferQueue对象
let num = 123;
let res = g_bufferQueue.take(num);
if (res != null) {
// 添加消费逻辑
}
}
}
function Main(): void {
let consumer: ConsumerTest = new ConsumerTest();
let producer: Producer = new Producer();
let threadNum: number = 10;
for (let i = 0; i < threadNum; i++) {
// 如下伪代码模拟启动多线程执行生产任务
// let thread = new Thread();
// thread.run(producer.run());
// consumer.run();
}
}
Actor模型
以下示例简单展示了如何使用基于Actor模型的TaskPool并发能力来解决生产者消费者问题。
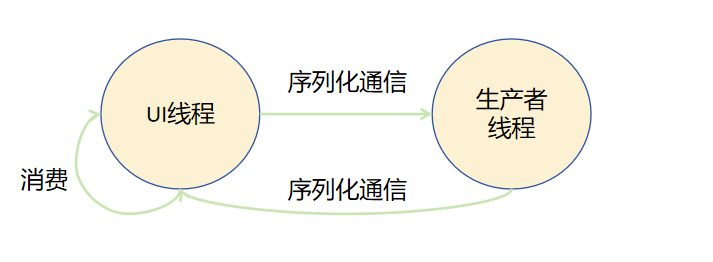
Actor模型中,不同角色之间并不共享内存,生产者线程和UI线程都有自己的虚拟机实例,两个虚拟机实例之间拥有独占的内存,相互隔离。生产者生产出结果后,通过序列化通信将结果发送给UI线程。UI线程消费结果后,再发送新的生产任务给生产者线程。
import { taskpool } from '@kit.ArkTS';
// 跨线程并发任务
@Concurrent
async function produce(): Promise<number> {
// 添加生产相关逻辑
console.info('producing...');
return Math.random();
}
class Consumer {
public consume(value: Object) {
// 添加消费相关逻辑
console.info('consuming value: ' + value);
}
}
@Entry
@Component
struct Index {
@State message: string = 'Hello World';
build() {
Row() {
Column() {
Text(this.message)
.fontSize(50)
.fontWeight(FontWeight.Bold)
Button() {
Text('start')
}.onClick(() => {
let produceTask: taskpool.Task = new taskpool.Task(produce);
let consumer: Consumer = new Consumer();
for (let index: number = 0; index < 10; index++) {
// 执行生产异步并发任务
taskpool.execute(produceTask).then((res: Object) => {
consumer.consume(res);
}).catch((e: Error) => {
console.error(e.message);
})
}
})
.width('20%')
.height('20%')
}
.width('100%')
}
.height('100%')
}
}
也可以等待生产者完成所有任务,通过序列化通信将结果发送给UI线程。UI线程接收后,由消费者统一消费结果。
import { taskpool } from '@kit.ArkTS';
// 跨线程并发任务
@Concurrent
async function produce(): Promise<number> {
// 添加生产相关逻辑
console.info('producing...');
return Math.random();
}
class Consumer {
public consume(value: number) {
// 添加消费相关逻辑
console.info('consuming value: ' + value);
}
}
@Entry
@Component
struct Index {
@State message: string = 'Hello World'
build() {
Row() {
Column() {
Text(this.message)
.fontSize(50)
.fontWeight(FontWeight.Bold)
Button() {
Text('start')
}.onClick(async () => {
let dataArray = new Array<number>();
let produceTask: taskpool.Task = new taskpool.Task(produce);
let consumer: Consumer = new Consumer();
for (let index: number = 0; index < 10; index++) {
// 执行生产异步并发任务
let result = await taskpool.execute(produceTask) as number;
dataArray.push(result);
}
for (let index: number = 0; index < dataArray.length; index++) {
consumer.consume(dataArray[index]);
}
})
.width('20%')
.height('20%')
}
.width('100%')
}
.height('100%')
}
}
TaskPool和Worker
ArkTS提供了TaskPool和Worker两种并发能力供开发者选择,两者之间实现的特点和适用场景存在差异。
实现特点对比
表1 TaskPool和Worker的实现特点对比
| 实现 | TaskPool | Worker |
|---|---|---|
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。 支持ArrayBuffer转移、SharedArrayBuffer共享和Sendable引用传递。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。 支持ArrayBuffer转移、SharedArrayBuffer共享和Sendable引用传递。 |
| 参数传递 | 直接传递,无需封装。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接传入并调用@Concurrent修饰的方法。 | 在Worker线程中解析消息并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage�中解析并赋值。 |
| 生命周期 | TaskPool自动管理其生命周期,无需关注任务负载。 | 开发者需自行管理Worker的数量和生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启64个Worker线程,实际数量由进程内存决定。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),长时任务无执行时长上限。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 从API version 18开始,支持配置Worker线程优先级。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务延时执行 | 支持。 | 不支持。 |
| 设置任务依赖关系 | 支持。 | 不支持。 |
| 串行队列 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
| 周期任务 | 支持。 | 不支持。 |
| 异步队列 | 支持。 | 不支持。 |
适用场景对比
TaskPool和Worker均支持多线程并发能力。由于TaskPool的工作线程会绑定系统的调度优先级,并支持负载均衡(自动扩缩容),相比之下,Worker需要开发者自行创建,存在创建耗时。因此,性能方面TaskPool优于Worker,推荐在大多数场景中使用TaskPool。
TaskPool偏向于独立任务,任务在线程中执行时,无需关注线程��的生命周期。超长任务(大于3分钟且非长时任务)会被系统自动回收。而Worker适用于长时间占据线程的任务,需要开发者主动管理线程的生命周期。
常见开发场景及适用说明如下:
-
运行时间超过3分钟的任务(不包括Promise和async/await异步调用的耗时,如网络下载、文件读写等I/O任务的耗时):例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。
-
有关联的一系列同步任务:例如在一些需要创建、使用句柄的场景中,每次创建的句柄都不同,必须永久保存该句柄,以确保后续操作正确执行,需要使用Worker。
-
需要设置优先级的任务:在API version 18 之前,Worker不支持设置调度优先级,需要使用TaskPool。从API version 18开始,Worker支持设置调度优先级,开发者可以根据使用场景和任务特性选择使用TaskPool或Worker。例如图像直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,且任务相对独立,推荐使用TaskPool。
-
需要频繁取消的任务:如图库大图浏览场景。为提升体验,系统会同时缓存当前图片左右各两张图片。当往一侧滑动跳到下一张图片时,需取消另一侧的缓存任务,此时需使用TaskPool。
-
大量或调度点分散的任务:例如大型应用中的多个模块包含多个耗时任务,不建议使用Worker进行负载管理,推荐使用TaskPool。场景示例可参考批量数据写数据库场景。
并发注意事项
-
避免在并发线程中操作UI
UI操作必须在主线程中执行。并发线程中操作UI可能导致界面异常或崩溃。
-
数据传递需支持序列化/反序列化
并发任务间传递数据时,对象必须是可序列化的(如基本类型、普通对象等),不可传递函数、循环引用、特殊对象(如Promise、Error)等。已完成(fulfilled或rejected)状态的 Promise可以被传递,因为其结果是可序列化的。
-
合理控制并发粒度
频繁创建和销毁并发任务(如Worker、Task)会带来额外性能开销,建议复用或使用任务池机制。
-
注意内存泄漏风险
避免在并发任务中持有外部对象的强引用,防止内存泄漏。
-
并发任务应具备独立性
并发任务应尽量不依赖外部状态,减少竞态条件(Race Condition)和同步开销。竞态条件是指多个线程或任务同时访问并修改共享数据,执行结果依赖于任务调度的顺序,可能导致数据不一致或不可预期的行为。